Week 10+ (Final Project) Updates
Table of contents
My final project is creating a Chat-GPT (or another large LLM) powered Tamagochi. There will be different characters that you can upload to the tamagochi, and you can talk to them using voice, and it will respond back using either actions, text and voice. The idea is that the Tamagochi pet can act as a friend, teacher, pet, or anything you can dream of as long as you can prompt ChatGPT to do something.
Hardware specifications
For the final project my minimum specifications are the following:
- Microphone input
- Speaker output
- Text to speech system (TTS) via cloud or local server
- Text processing via GPT-3/4 API
- Speech to text via cloud or local server
- Screen output to display the tamagochi pet, some basic statistics about how often you’ve interacted, and other statistics, for example your language proficiency improvement (rated by ChatGPT), number of tokens used (to keep track of costs).
- Buttons to interact with the the pet and move from screen to screen.
Initial characters
There are two characters that I want to implement on my tamagochi, a conversational language teacher and a therapeutic digital pet that you have to take care of, talk to, and feed.
Conversational chinese language teacher
The most difficult part of learning a language is being able to fluently converse and use the vocabulary and grammar structure that you have learned through text-books and applying them in real-life situations. There is no straight-forward solution to this problem, apart from finding friends who are willing to converse with you in a language or a tutor to help you practice. However, this is both expensive and somewhat inconvenient. Furthermore, learning to pronounce words accurately and fluently is also a difficult task with traditional self-learning methods such as DuoLingo, since it does not give you the opportunity to practice speaking with a native speaker.
Using currently available text to speech models, that are produce speech indifferentiable to that of a native speaker, we can create a conversational language teacher that can help you practice speaking and listening to the language. Since the teacher is powered via ChatGPT, you would be able to choose any topic of conversation that you want, for example, interacting with a restaurant water, a friend, and even in business and formal settings.
Ideally, the teacher will be able to respond to your questions and comments, and will be able to correct your pronunciation and grammar mistakes. The teacher will also be able to give you feedback on your progress, and will be able to give you tips on how to improve your language skills. However, these are left as stretch goals.
Update 1: Final Project MVP
This week I worked on the most difficult part of the project: linking together the different parts API’s and checking the quality of different text-to-speech models.
With the minimum viable product, I was focused only on getting the input and output linked up, however not in the most efficient way.
I used the microphone from the ESP32 to record a .wav file onto the internal SPIFFS memory. This was hard-coded to be a 20 second .wav file. I then sent this file to my computer, which forwarded the file to the Microsoft Azure Speech to Text service via an API. The Azure Speech to Text service then returned the recognized words as a string back to the computer, where it was then sent to OpenAI’s ChatGPT Completions API. The returned text is send back to the ESP32, which then displays the text on the screen.
The design chart is below.
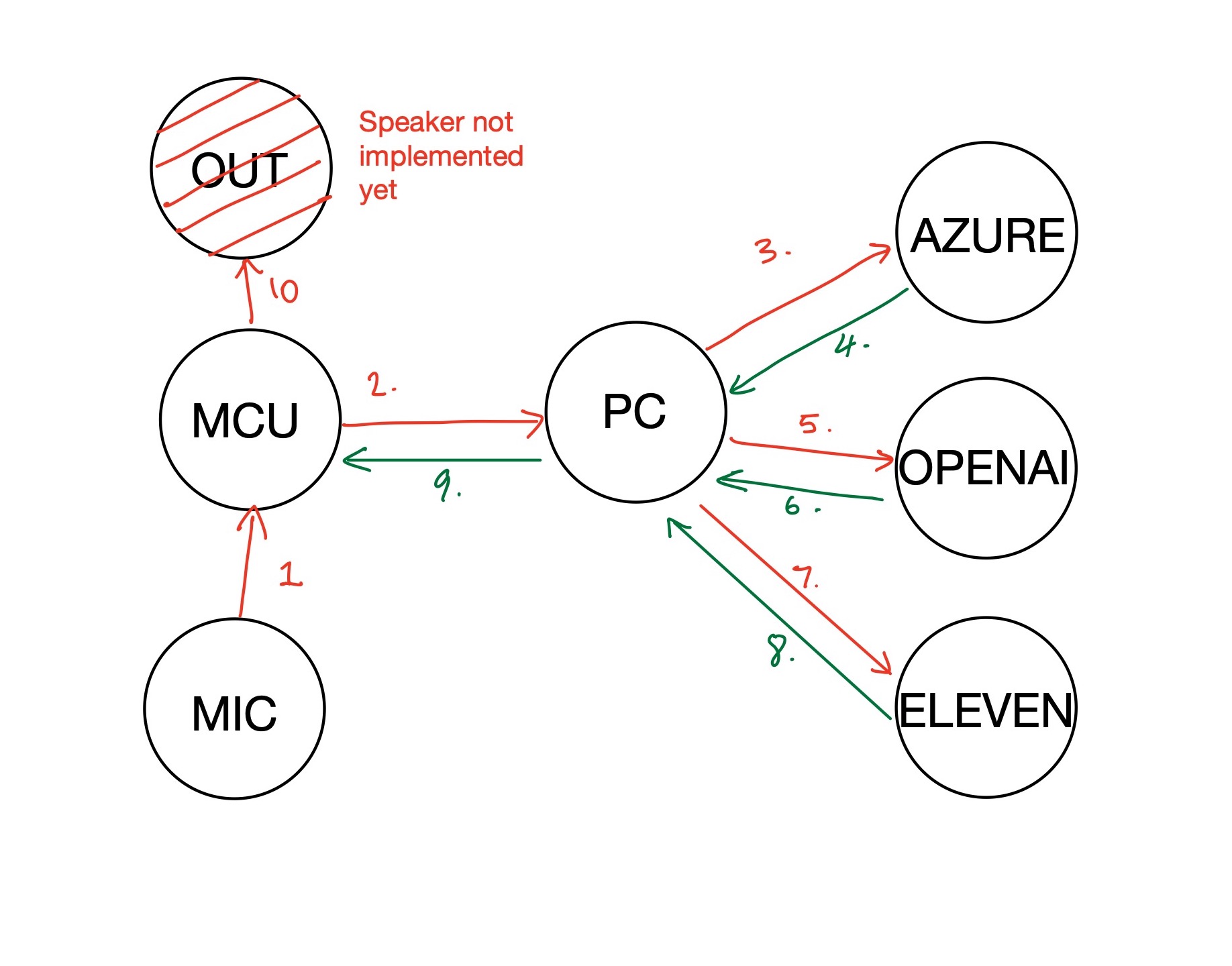
Currently nothing is asynchronous and I still need to investigate if this is possible. The MVP system is designed as follows:
- MCU records 20 seconds of audio data from I2S microphone into SPIFFS Internal Storage as
.wavfile - MCU send ‘.wav’ file to computer via WiFi using HTTP Client.
- PC sends ‘.wav’ file to Azure Speech to Text API
- Azure Speech to Text API returns recognized text to PC.
- PC reformats recognized text and sends recognized text to OpenAI ChatGPT API.
- OpenAI ChatGPT API returns text completion to PC.
- PC sends text completion to Eleven TTS API.
- Eleven TTS API returns
.mpegfile to PC. - PC sends
.mpegfile to ESP32 via HTTP Client. - MCU displays text and plays audio on OLED and speaker.
There are many optimizations that can be made to this system, and I will investigate a few.
- Investigate the possibility for streaming data via websockets to reduce latency.
- Investigate the possibility of removing the PC and have everything route directly through the MCU.
- Implement the speaker (I couldn’t get it working)
Here is a photo of the MVP which is just a breadboard unit.

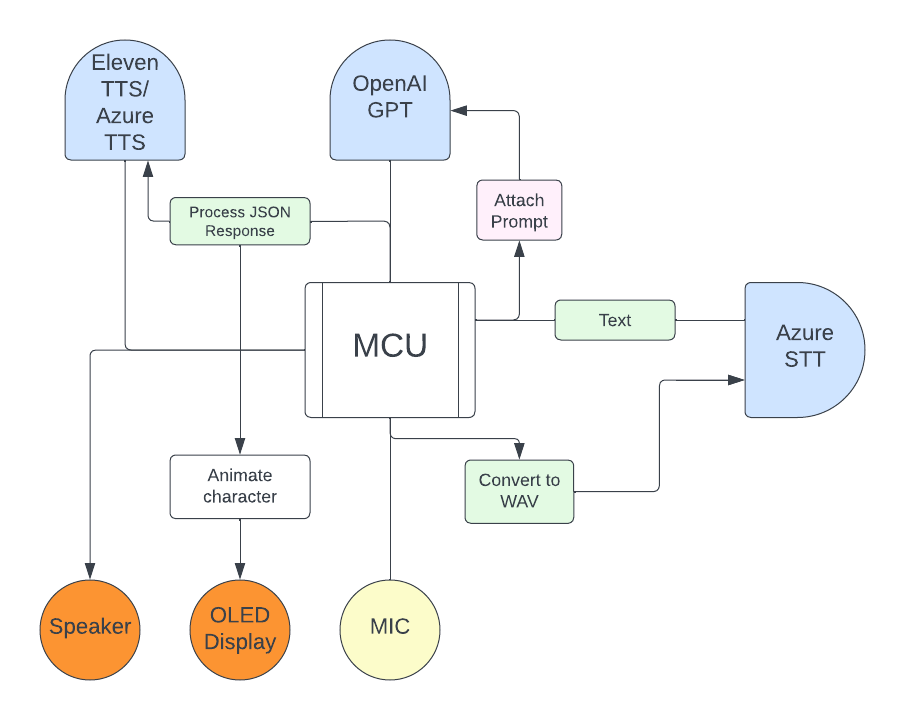
Here is a ideal refined system diagram for my next iteration.